La gestion de la montée en charge d’une application web est très importante pour assurer sa performance et sa disponibilité. Avec l’avènement du cloud, il est facile d’augmenter les ressources matérielles du serveur qui héberge notre application (scalabilité verticale). Cependant, cette approche a des limites, nous ne pouvons pas ajouter continuellement du CPU ou de la RAM à un serveur. De plus, si ce serveur tombe en panne, toute l’application devient indisponible. C’est là que faire usage de la scalabilité horizontale devient intéressante, car celle-ci permet de répartir la charge sur plusieurs serveurs.
Dans cet article, nous allons explorer les bonnes pratiques pour déployer sans downtime sur un cluster une application todo-list dockerisée puis voir la mise à l’échelle de l’application grâce à la scalabilité horizontale.
Mise en place du cluster
Un cluster de machines comme son nom l’indique est un ensemble de serveurs interconnectés pour héberger une ou plusieurs applications. Ces serveurs peuvent être créés facilement dans le cloud (par exemple sur AWS, Google Cloud, Microsoft Azure ou Digital Ocean). Par ailleurs, il est nécessaire d’utiliser un orchestrateur (Swarm, Kubernetes ou Mesos…) pour gérer le cluster, notamment l’orchestration des serveurs et des services de notre application.
Pour cette démonstration, nous allons utiliser Docker Swarm pour déployer notre application composée d’une base de données MySQL et d’une interface web développée avec Node.js. Vous pouvez retrouver l’original du code source de l’application sur ce dépôt GitHub.
Nous allons utiliser la plateforme play-with-docker (libre à vous d’utiliser un fournisseur cloud de votre choix) pour créer un cluster de 3 nœuds : un manager qui gère l’orchestration (nœud 1 : 192.168.0.8) et deux workers pour l’exécution des services de l’application (nœud 2 : 192.168.0.7 et nœud 3 : 192.168.0.6). Il faut noter qu’en plus de son rôle de coordinateur du cluster, le manager peut également participer à l’exécution des services de l’application.
Une fois les serveurs créés, nous allons initialiser Swarm sur le manager en exécutant la commande suivante :
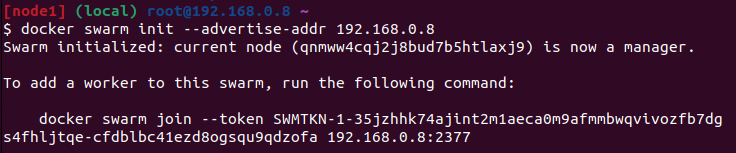
Ensuite comme indiqué par Swarm, il faut exécuter la commande join générée, sur chacun des nœuds 2 et 3 pour les joindre au cluster.
Ces étapes étant faites, notre cluster est maintenant prêt à héberger notre application todo-list.
Création du stack de l’application et stratégies de déploiement
Comme notre application contient plus d’un service, nous allons créer un stack simple pour décrire la façon dont chaque service de l’application doit être déployé, ainsi que le réseau et les volumes nécessaires.
# Stack de déploiement todo-list-stack.yml
version: '3.8'
services:
app:
image: node:22-alpine
command: sh -c "yarn install && yarn run dev"
ports:
- "3000:3000"
working_dir: /app
volumes:
- ./:/app
environment:
MYSQL_HOST: mysql
MYSQL_USER: root
MYSQL_PASSWORD: secret
MYSQL_DB: todos
deploy:
replicas: 3
restart_policy:
condition: on-failure
max_attempts: 3
update_config:
parallelism: 2
delay: 10s
placement:
constraints:
- node.labels.dedicated != mysql
networks:
- todo-network
mysql:
image: mysql:8.4
volumes:
- todo-mysql-data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: secret
MYSQL_DATABASE: todos
deploy:
placement:
constraints:
- node.labels.dedicated == mysql
restart_policy:
condition: on-failure
max_attempts: 3
networks:
- todo-network
volumes:
todo-mysql-data:
networks:
todo-network:
driver: overlay
Pour avoir un déploiement sans interruption et garantir une haute disponibilité, nous répliquons le service app pour avoir trois instances (ou tasks) de ce service. Grâce à la stratégie de mise à jour parallelism, seules deux de ces tasks sont mises à jour en parallèle, ce qui permet de maintenir la troisième task active pour répondre aux requêtes. De plus, un délai de 10 secondes est introduit avant la mise à jour de la dernière task, assurant ainsi un déploiement sans downtime.
Pour avoir de bonnes performances pour le service MySQL, une contrainte de placement spécifique a été appliquée pour déployer la base de données sur un nœud dédié (nœud 3), en utilisant la contrainte node.labels.dedicated == mysql. Cette contrainte de placement nécessite de créer le label en exécutant la commande suivante sur le manager :
docker node update --label-add dedicated=mysql node3
Les deux services communiquent à travers un réseau overlay, qui permet de relier les conteneurs déployés sur les différents nœuds du cluster.
Pour déployer notre stack, nous lançons la commande suivante sur le manager:
docker stack deploy -c todo-list-stack.yml todo-list-stack
Une fois le déploiement terminé, nous pouvons surveiller l’état du cluster et des services en utilisant Docker Swarm Visualizer accessible sur ce lien.
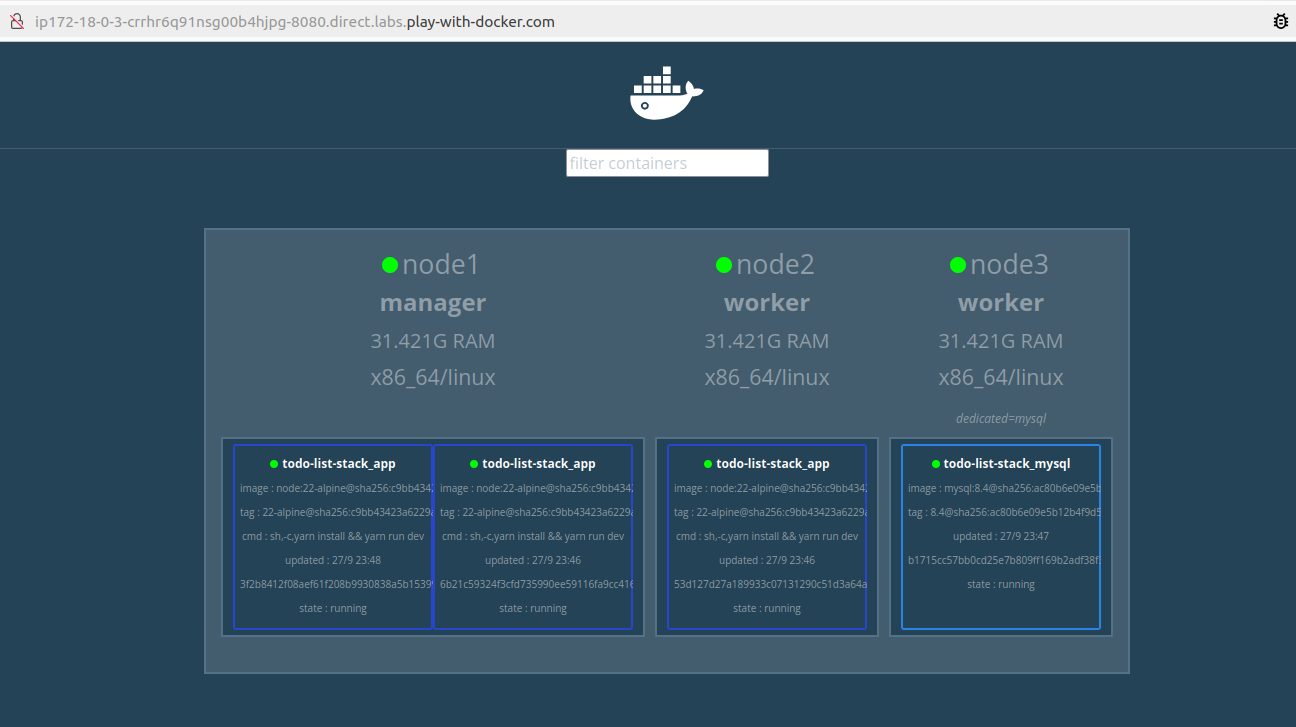
Réplication et scalabilité horizontale
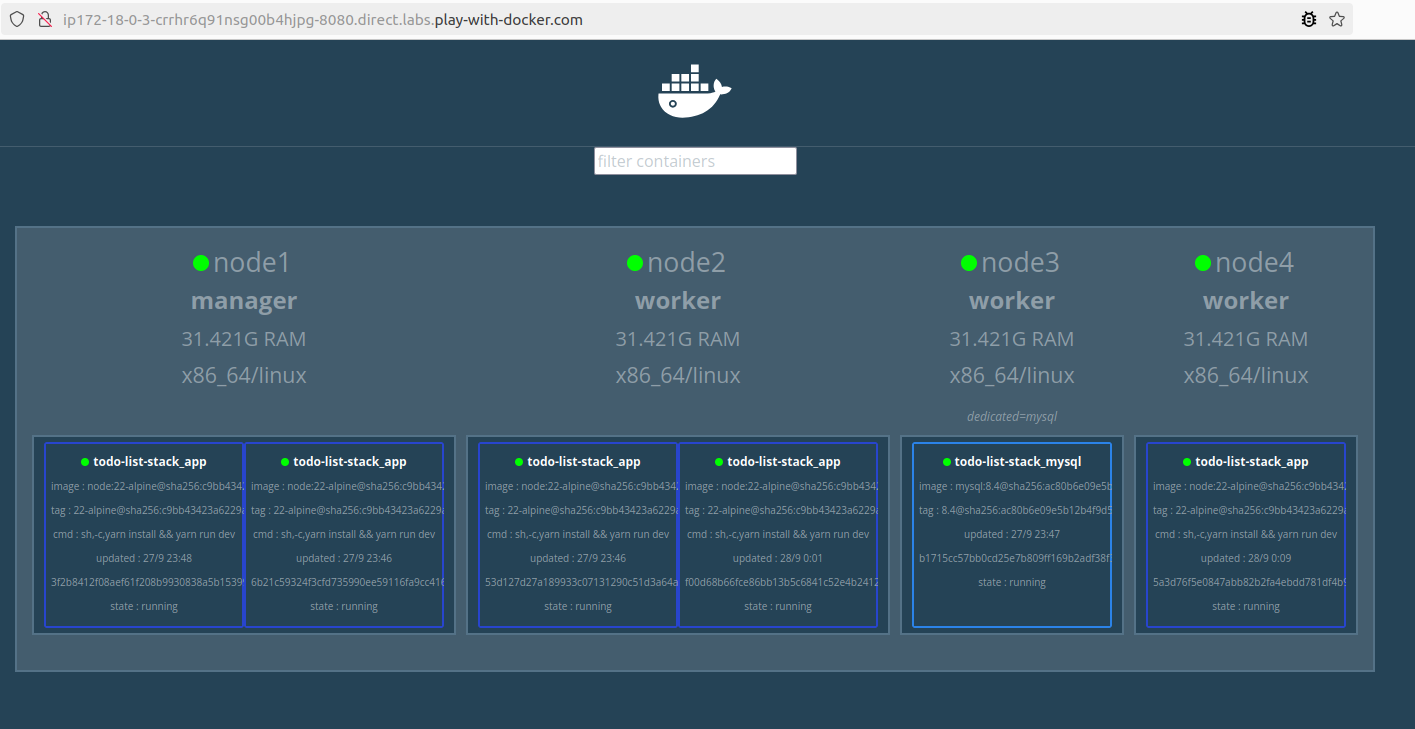
Comme mentionné dans l’introduction, pour assurer la disponibilité et une bonne performance d’une application, il peut être nécessaire d’augmenter le nombre d’instances d’un service ou d’ajouter des nœuds supplémentaires sur le cluster. Par exemple, pour faire face à une éventuelle montée en charge, nous allons ajouter un quatrième serveur (nœud 4 : 192.168.0.5) au cluster et nous montons aussi le nombre de tasks du service app à 5 grâce à la commande suivante :
docker service scale todo-list-stack_app=5
En exécutant cette commande, Swarm va augmenter le nombre d’instances du service app et répartir les tasks de manière optimale entre les nœuds disponibles dans le cluster.
Nota Bene : La gestion d’un cluster en production peuvent engendrer des coûts assez conséquents et est plus adapté aux projets d’entreprises, qui nécessitent une haute disponibilité. Si vous gérez un site personnel, il est souvent plus simple de déployer votre application sur un serveur unique à l’aide d’outils classiques comme Docker Compose.
La montée en charge d’une application peut être gérée de manière efficace grâce à la réplication et la scalabilité horizontale. Avec cet exemple, nous avons vu comment configurer un cluster, déployer une application todo-list sur plusieurs serveurs, et mettre en œuvre des stratégies de réplication et de scalabilité pour avoir de meilleures performances.